My Harvard CS50 Notes - Lecture 2 - Arrays
I'm following the online Harvard CS50 course and I'm making my notes public!
Lecture
Compiling
When we use "make", we create machine code. However, "make" is actually a program that runs a compiler for us: clang (short for C Language).
We can also use this command instead of make, but it isn't as user friendly because it just outputs a file called a.out.
For example, if you want to compile a program called 'hello.c', you'd do it like this:
clang hello.c
./a.outYou can also specify a name:
clang -o hello hello.c
./helloIt gets even more complicated when we use a library, because we have to specifically tell the compilter to include this library.
clang -o hello hello.c -lcs50
./helloSo make is useful because it saves us from doing this whole bit.
Compiling actually one of four steps that are necessary to transform source code to machine code:
- Preprocessing
- Compiling
- Assembling
- Linking
Preprocessing
When we do something like #include, this hashtag symbol is actually a preprocessor directive.
The preprocessor checks all the #include's, goes to those files and essentially copy's and paste's the code on the place of the #include.
Compiling
After the preprocessing, the code gets compiled in assembly language. This is what humans wrote before C existed (and before that, people programmed in binary. Yikes.)
Assembling
Take the assembly code and convert it to binary. This is actually why clang creates the file called "a.out" (Assembly Output).
Linking
If you add this to your code:
#include <cs50.h>The file cs50.h exists somewhere on the hard drive of our environment. This file just includes prototypes of functions (like get_string()).
There is actually another file, called cs50.c that includes the implementation of these functions.
Hello.c gets combines with cs50.c that gets combined with stdio.c.
Clang (our compiler) needs to combine each of these files in binary. But now we have three seperately compiled files. The fourts and final step (linkin) takes all of these 3 files and combines it into 1 file.
Decompiling
You can also take the 0's and 1's and reverse engineer them into source code, but it's easier said than done. There are multiple ways to solve the same problem in programming. You'll lose the variable names, function names, etc so you may have C code, but it's going to be really tough to put all this together.
Debugging
If you end up with an unexpected output, you can use printf to see the value of a variable to understand what's going on.
But when you have too many printf's, the output (and code) get's messy so you need a better debugging tool: a debugger.
We'll use the command debug50 to easily start the debugger.
debug50 ./hello.cThis will output an error that we haven't set any breakpoints. You can do this by hovering over the gutter of VS code (left side) and click on a line. This command will now open some other windows, including the values of your variables.
When you don't assign a value to a variable, it will often contain a "garbage value" that seems random
Now we can use the buttons.
With 'step over' we're going to execute the line (it doesn't skip it!)
If we use 'Step into', we'll dive into the code. So for example when you set a breakpoint on a line that includes a function print_column and you step into it, you'll move the debugger to the inside of the print_column function.
Get into the habit of using the debugger so you don't waste time by building up tech debt by using printf all the time.
Rubber Duck Debugging
This is a form of method where you simply talk to a rubber duck (or another object). You end up hearing any illogic in your reasoning.
Memory
- bool (1 byte)
- int (4 bytes)
- long (8 bytes)
- float (4 bytes)
- double (8 bytes)
- char (1 byte)
- string (? bytes)
Memory (RAM / Random Access Memories) have chips that include bytes. We can think of memory of having addresses to address each of the bytes individually. So if you're storing just a single byte (a char for example), it might take up just the top left corner (if you divide the memory in a grid of bytes).
You can see memory as a grid of bytes.
So if you have an integer (4 bytes), it would take up 4 cells in the memory grid.
Arrays
Let's say you have this code:
int score1 = 70;
int score2 = 35;
int score3 = 80;This isn't good design, because what if you want to add scores.
This is a perfect fit for an array.
An array is a series of values back to back to back in memory (no gaps, no fragmentation).
// Define a variable that has room for 3 integers
// The computer will store it back to back to back in the memory
int scores[3];
// Assign values
scores[0] = 70;
scores[1] = 35;
scores[2] = 80;If you want to get the input from the user, you could use a loop
int scores[3];
for(int i = 0; i < 3; i++){
scores[i] = get_int("What is the score: ");
}Global variables
If you put a variable on top of all the functions (outside of any variables), you share this variable with all the functions. This is generally okay if you use a constant.
C doesnt have any way to calculate the length of an array (unlike languages like JavaScript where it's very easy).
So let's say that you have a function that calculates the average of the values in a array. You'll need to pass both the array, and also the length of the array as parameters.
float average(int length, int array[]){
int sum = 0;
for(int i = 0; i < length; i++){
sum += array[i];
}
return sum / (float) length;
// By typecasting length to a float, this will return a decimal number
// Because when you do math and at least 1 of the variables is a float, C will transform everything to a float. This would be the same as passing 3.0 as the value for 'length'
}String
What happens when you store a variable 's' with a value of 'HI!'.
In the memory (grid), everything is basically just 1 byte. So even though you haven't created an array, it will be stored in the memory like:
s[0] = "H";
s[1] = "I";
s[2] = "!";But how does a computer where a string ends? It's not a fixed amount of bytes like an integer or double.
There is actually an empty byte at the end of every string that just includes all 0 bits.
s[3] = 00000000Every string is actually n + 1 bytes long.
Every string in the world ends with \0, because this is the char representation for 0.
We can also create an array for string:
string words[2];
words[0] = "HI!";
words[1] = "BYE!";In this case, you have an array of strings. But each string will also be it's own array of characters. So if you wanted to get 'i', you'd do words[0][1]
Calculate length of string
The important thing to know here, is that every string ends with the character \0. So you can write a function that loops through all the characters until it gets a 0.
int string_length(string s){
int n = 0;
while (s[n] != '\0'){
n++;
}
return n;
}There is also a library called string.h that includes similar functions that gives you more possibilities to work with strings.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void){
string name = get_string("Name: ");
int length = strlen(name);
printf("%i\n",length);
}
This code will print out the complete string (so it's essentialy the same as using %s):
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void){
string s = get_string("Input: ");
printf("Output: ");
for(int i = 0; i < strlen(s); i++){
// Print out each character
printf("%c",s[i]);
}
printf("\n");
}
Note that we use a function call in our for loop. This means that we keep asking the computer to run the strlen function. It would be a better idea to put this in a variable. You can do this inside the for loop. Where you initialize the i, you can simply initialize other variables as well.
Note: to use this trick, the variables have to be the same type (in this case an integer)
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void){
string s = get_string("Input: ");
printf("Output: ");
for(int i = 0, n = strlen(s); i < n; i++){
// Print out each character
printf("%c",s[i]);
}
printf("\n");
}
Transform string to uppercase
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void){
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++){
// We want to force this character to uppercase
if(s[i] >= 'a' && s[i] <= 'z'){
// This means that the current value is lowercase
// We want to force it to uppercase
// In ASCI, the difference between the lowercase and uppercase is 32.
printf("%c",s[i] - 32);
} else {
// It's already uppercase or it's punctuation
printf("%c",s[i]);
}
}
printf("\n");
}
We can also do this by using the library ctype.h that has a toupper function. This function also checks if the character is already uppercase. If that's the case, it just passes through the value so we don't need that if-else statement anymore.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
#include <ctype.h>
int main(void){
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++){
printf("%c",toupper(s[i]));
}
printf("\n");
}
Command line arguments
You can write code that takes command line arguments, by using argv (argument vector, which is essentially the same as an array) as parameter.
The integer argc will include the number of args typed.
#include <stdio.h>
int main(int argc, string argv[]){
}For example, this will output your name when you run ./greet teebow
#include <stdio.h>
#include <cs50.h>
int main(int argc, string argv[]){
printf("Hello, %s",argv[1]);
}
We use argv[1] because argv[0] will include the name of your program (greet.c in this case)
When using this approach, we'll need to check if the user has specified the right amount of arguments.
#include <stdio.h>
#include <cs50.h>
int main(int argc, string argv[]){
if(argc == 2){
printf("Hello, %s",argv[1]);
} else {
printf("Please enter the right amount of arguments");
}
}
If we don't even know how many arguments there are going to be, we can combine some of the ideas we saw previously and loop through the array.
#include <stdio.h>
#include <cs50.h>
int main(int argc, string argv[]){
for(int i = 0; i < argc; i++){
printf("%s\n",argv[i]);
}
}
Exit status
All of the programs eventually exit with an exit status. It's by default always 0 (means that everything is okay). Everything else is bad. 1 is bad, -1 is bad, etc.
This is why we use an 'int' for our main function.
#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[]){
if(argc != 2){
// Not the right amount of arguments
printf("Missing command line arguments");
return 1; // You could also return 1132 or any other number but it's a good idea to start at 1
}
printf("hello, %s\n",argv[1]);
return 0; // Success
}
Now when something goes wrong, we can track back where it went wrong.
If you want to see what the most recently executed program exited with, you can enter this in the terminal:
echo $?If you use unit tests, those tests can detect the status code.
Cryptography
Plaintext is any message written in english, ciphertext is what you want to convert it to before handing it off to strangers or servers on the internet. The black box is the 'cipher', which is the algorithm that will scramble the information in a reversible way.
Most ciphers take as input a message, and a key. It's a really big number made up of lots of bits so that nobody can guess the key.
Example:
Message: HI!
Key: 1
You have to agree with the recipient of the message that the key is 1. So the output is IJ!
This is known as the caesar cipher. He used to use the key 3. 13 is more common, it's called rot13 which means that it rotates the letters of the alphabet by 13. It would turn HI to UV.
In the example above, some information will leak (the exclamation mark). It's not a safe algorithm because if you know that it's using the english alphabet, you could brute force it.
For decryption, if the key is 1, you just do minus 1. If the key is 13, you do minus 13.
Message: UIJT XBT DT50
Key: -1
Output: THIS WAS CS50
Shorts
Functions
By using functions, you don't have to write all the code in the main function.
A function is basically a black box with a set of 0+ inputs and 1 output. We call it a black box because if we aren't writing the functions ourselves, we don't need to know the underlying implementation.
It's important that you choose clear, obvious names so that the behaviour of the function is predictable.
Functions allow us to:
- Organize
- Simplify
- Reuse
We need to declare the functions atop of the main code, so that the compiler knows that we're going to define a function later on.
Function declarations follow this form:
return-type name(argument-list)Variables and scope
Scope defines from which functions a varibale may be accessed
- Local variables: can only be accessed withing the functions in which they are created
- Global variables can be accessed from every function. They are declared outside of all functions (usually under the #include lines, and on top of the main void)
Arrays
Array declarations follow this form:
type name[size]C does not prevent you to go "out of bound", so be very careful!
We can declare an initialize an array simultaneously.
bool truthtable[3] = { false, true, true };If we do it like this, we actually don't need to define the length of the array beforehand. So this would work as well:
bool truthtable[] = { false, true, true };We can treat individual elements of arrays as variables, but we cannot treat entire arrays themselves as variables. For example, you cannot assign 1 variable to another. If you want to do that, you'd actually need to use a loop to copy one array into another.
Command Line Arguments
If we want the user to provide data to our program befor eour program starts running, we need a new form: command line arguments
int main (int argc, string argv[]){
}argc stands for argument count (although you can give it another name). It stores the number of command line arguments the user typed
./greedy
// argc is 1
./greedy 1024 cs50
// argc is 3Section
The section didn't introduce or clarify a lot of things that weren't shown in the lecture. However, some things to remember:
- If you're in a loop and you want to exit the program, you can do return 0
- You have to always watch out for "out of bounds" bugs that happen a lot when working with arrays.
atoi
Say that you let the user run the mario program, and in the command they can provide an integer for the height of the pyramid.
The command would be like this:
./mario 8In C, you can get that input by using argv[]
int main(int argc, string argv[]){
}But as you can see, argv holds an array of strings. So if we simply do this, we'd get an error:
int main(int argc, string argv[]){
int height = argv[1]
}ERROR: Imcompatible pointer to integer conversion initializing 'int' with an expression of type string.
We can fix this by using the atoi function that lives in the #include <stdlib.h> library.
int main(int argc, string argv[]){
int height = atoi(argv[1]);
}Segmentation fault
Another common error is the 'segmentation fault'. This usually occurs when you go out of bound in your array. So for example if you request the value of argv[1] but you don't include this argument on the command line, you'd get a segmentation error.
This is why you use argc to check if the user has provided the right amount of arguments.
Problem Sets
Scrabble
In the first problem set, we have to create a program that takes two strings as an input. The program then assigns a scrabble value to each of the strings, and compares the values to check who won.
The hardest thing about this exercise, is figuring out how you can get the right scrabble value per letter.
So we make an array that includes all the scrabble values from A to Z.
int points[] = {1, 3, 3, 2, 1, 4, 2, 4, 1, 8, 5, 1, 3, 1, 1, 3, 10, 1, 1, 1, 1, 4, 4, 8, 4, 10};
Now if we have a word like 'CODE' and we loop through all the digits, we want to know what value to assign to C, what value to assign to O, etc.
So in fact, we have to find the index of the array that corresponds with the right value.
The most important thing to know here, is that (lowercase) 'a' is represented in ASCII as 97. b is 98. c is 99, etc.
So if you see the 'c' of 'code' as a 99, you have to subtract 97 from that value to get the index of the points array.

Check out my code here:
 262588213843476
262588213843476
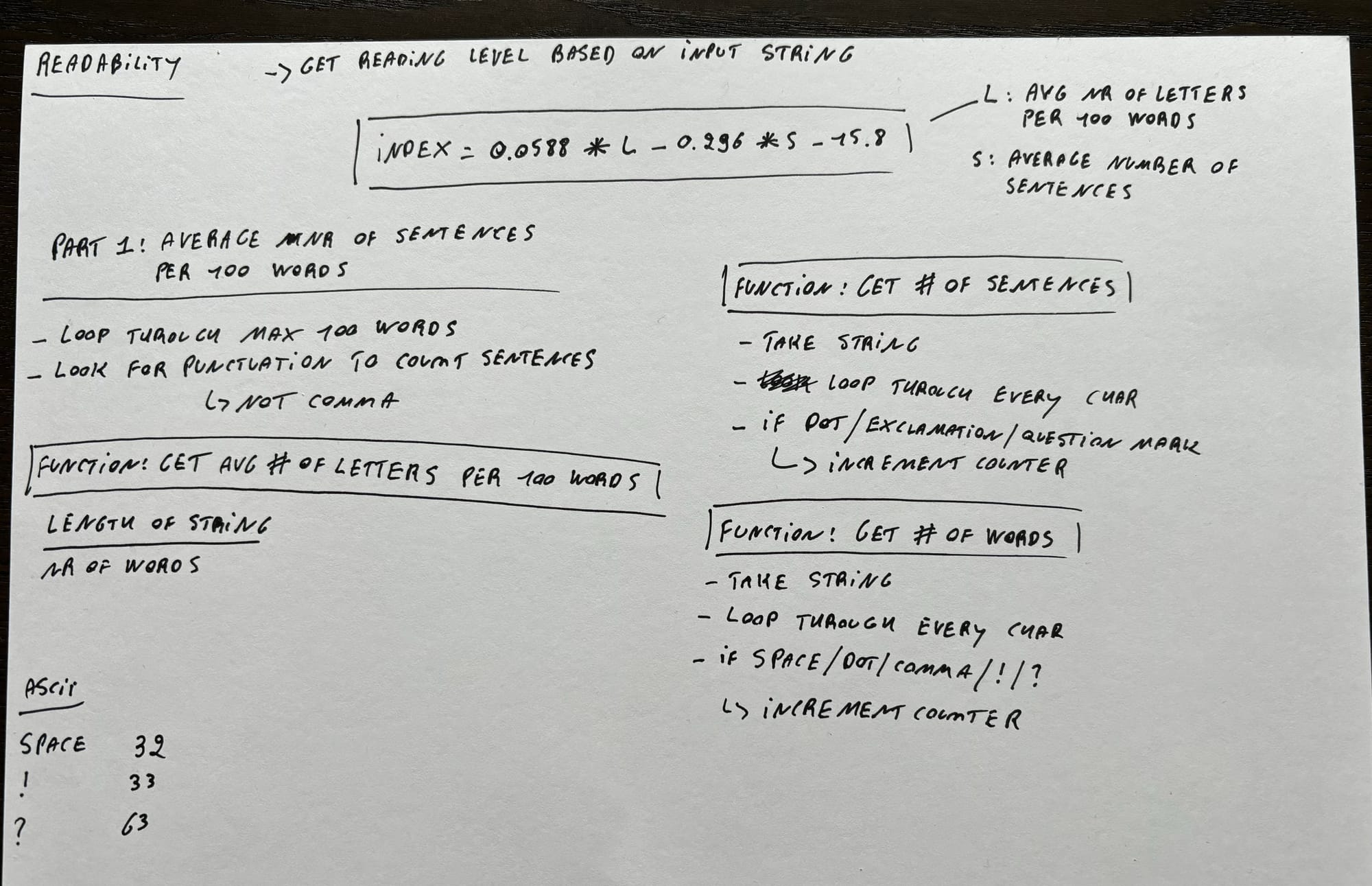
Readability
This pset challenges you to write a piece of software that takes some text, and it returns the reading level of that text. We do that by using the Coleman Liau Index.
This problem set set wasn't actually that hard to figure out and the programming part was pretty straightforward, but I kept ending up with the wrong value of the Coleman Liau Index.
It turned out that I couldn't just use the default strlen function, because that also counts spaces and other punctuation marks. So once I wrote my own function that builds upon the strlen function (but subtracts the amount of punctuation marks and spaces), I finally got the right results.
Check out my code here:
thibaultseynaeveCaesar
This problem set asks you to write a program that takes a key (numeric value) from the user, along with a string and converts it to ciphertext. The new character is the alphabetic position of the old character, plus the key. So 'A' with a key of 2 would become 'B'.

Again, this wasn't really a programming challenge per se, but just like the other problem sets require some mathematical and computational thinking. For example, I lost a lot of time because I forgot to manually add the sentinel value for the string (The '\0' that signals the end of the string) so I got unexpected results.
Check out my code here (I should really clean it up a bit by putting it in functions instead of dumping everything in the main function, but I'd rather move on with the next (and final) problem set.
thibaultseynaeveSubstitution
To check for repeated character, my first idea was to calculate the sum of all the ASCII values for A to Z. Now when you get a key from the user, you loop through every digit and you count the ASCII values of all the characters. If that value doesn't equal the sum of the ASCII values from A to Z, you know that a letter has been used double. However, this would work if the key is all uppercase or all lowercase, but not with a mix. So instead, I chose to write a nested loop that loops through every digit of the char array, and check the current digit with every digit in the array. When the character appears more than once, you know that a letter has been used twice (or more).
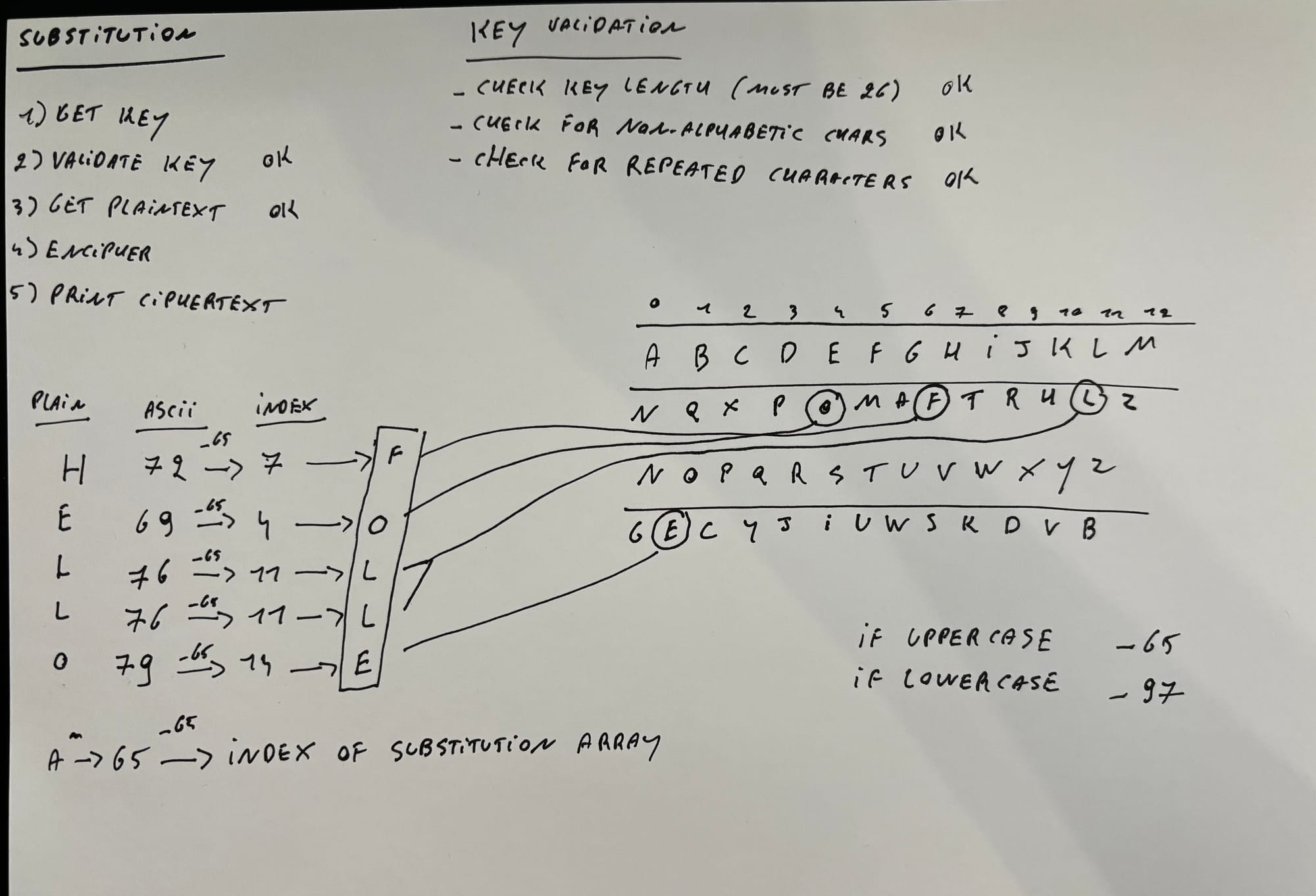
Other than that, it's pretty similar to the 'Caesar' problem set and I was able to reuse a lot of my code.
Check out the code here:
thibaultseynaeve