My Harvard CS50 Notes - Lecture 3 - Algorithms (Section & Problem sets)
These are some notes on the section and problem sets for week 3 of the Harvard CS50 course.
Section
Searching and Sorting algorithms
Let's review the algorithms we saw to search and sort.
Linear Search
If we want to search in a list of names that's not ordered, we can use linear search. We look at each item in the array individually and ask "is this the item we're looking for".
What's the greatest number of steps this algorithm will EVER take
- In worst-case you have to go through the whole array
- O(n)
What's the fewest number of steps this algorithm could EVER take
- In best-case (you get lucky), you find what you're looking for at the first item of the list
- Ω(1)
Binary Search
If the data is sorted, we can use binary search. We divide the array in half, and ask ourself "Is this what we're looking for?". If that isn't the case, we ask "is the person we're looking for in the left half, or in the right half" and we repeat this process.
What's the greatest number of steps this algorithm will EVER take
- In worst-case, we ask ourself "how often can we divide the data by 2", which is the same as log(2)n
- O(log2n)
What's the fewest number of steps this algorithm could EVER take
- In best-case (you get lucky), you find what you're looking for at the middle of the list (the first place you're looking for)
- Ω(1)
Conventions
Say you have an algorithm that takes 2 (and only 2) steps in the best case. In that case, you'd think that the big omega notation is Ω(2), but computer scientists have a convention where they think about things "on the order of". Whether it takes 2,3,4,... steps, we simply say it takes Ω(1) steps to say that it takes a finite amount of steps.
Struct
If we want to store related variables (for example, a user has a name, an age, a favorite food, etc) we can use structs.
The kind of data we store for a structure are called the 'members'.
typedef struct{
string name;
int votes;
} candidate;So in the example above, the members are 'name' and 'votes'.
A struct is basically a template, a blueprint. When it's defined, we can create variables like this:
candidate president;
president.name = "samia";
president.votes = 100;Recursion
Recursion is not always the best way to solve a problem, but when it is, it's a really elegant soluation.
For example, when you want to output the factorial value of a number.
1! = 1
2! = 2 * 1
3! = 3 * 2 * 1
4! = 4 * 3 * 2 * 1So if you want the factorial of 3, you'd need 3 multiplied the factorial of 2.
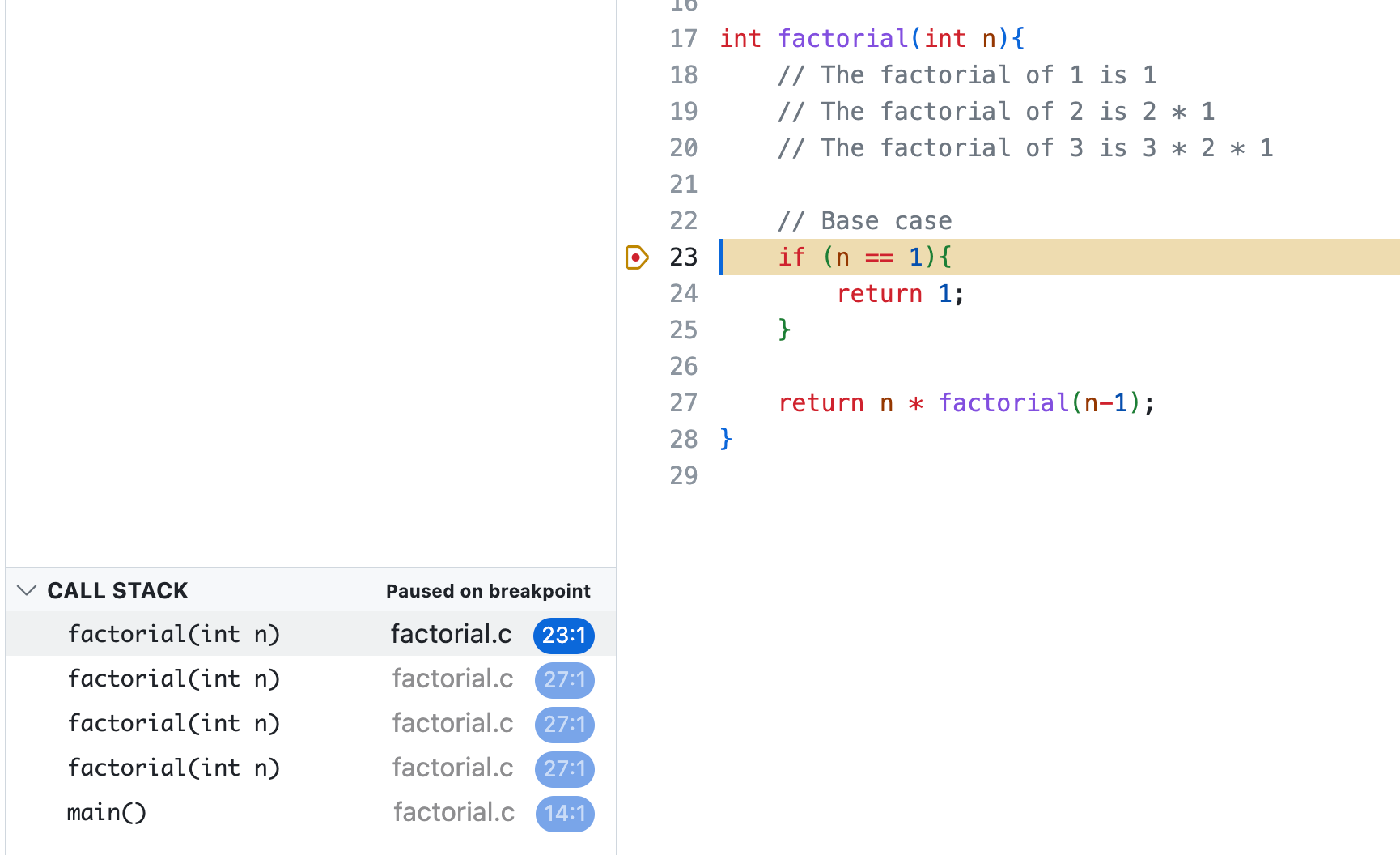
Recursion functions work by "stacking" functions on the call stack, and then resolving them all at once. You can see this call stack when you use debug50.
The last function you add to the stack is the first one that'll get resolved. So that's why this works. It stacks all the function, and then it does the factorial of 1, he returns that value to the function that does the factorial of 2, etc until you finally do the last factorial function in the call stack and return the value to the main function.
#include <cs50.h>
#include <stdio.h>
int factorial(int n);
int main(void){
// Get positive value for n
int n;
do{
n = get_int("n: ");
} while (n < 0);
// Print factorial
printf("%i\n",factorial(n));
}
int factorial(int n){
// The factorial of 1 is 1
// The factorial of 2 is 2 * 1
// The factorial of 3 is 3 * 2 * 1
// Base case
if (n == 1){
return 1;
}
return n * factorial(n-1);
}
Problem Sets
Sort
This pset isn't really a coding challenge, but more of a puzzle. You get three programs (but you can't see the code): sort1, sort2 and sort3. Each program uses one of these sorting algorithms: selection sort, bubble sort and merge sort. You have to figure out which sorting method belongs to each program.
To do this, you use the program time that will print the total amount of time it took to run the program. You also get some datasets (with ordered date, reversed data or unordered random data).

Let's first run the program and put the results of the time program in a table.

So with this data put in a table (I also ran the 50K datasets, but these are on the back of the sheet), we can draw our conclusions.
- We know that Bubble Sort will be significantly faster in a best case scenario (which means that the data is already sorted). This corresponds with the data we see in the first program.
- We know that Merge Sort is the fastest algorithm in the worst scenario. We can clearly see this in our datasheet with the data for the random data. Where the running time of sort1 and sort3 gets significantly longer, the running time for sort 2 stays about the same.
- Selection Sort is the slowest algorithm for large datasets (since it has to go through all the elements in the array, no matter if they are sorted or unsorted). We can clearly see this for sort3, where the runtime for the sorted array gets significantly longer when the data set increases.
Plurality
In this problem set, you specify the names of candidates on the command line. After that, you ask the user how many people will vote. Then, you ask the user for a name (string) for every voter. After that, you print out who won the election (if there are multiple winners, you print out multiple names).

So this was actually one of the easier problem sets, where I didn't even get any errors and got all happy faces in the check50 output. So that could mean that:
- CS50 has made me a computer scientist wizard
- I've done something very wrong and I should probably have used a way more complex solution here
I didn't use recursion for this problem set, and maybe I should have.
Nonetheless, this is my code:
 thibaultseynaeve
thibaultseynaeveRunoff
So this is definitely one of those problem sets that seems a lot more intimidating than it actually is. Don't freak out and really take your time to understand the problem set.
I took about an hour to read the problem set, go through the walkthrough video, write everything down, print out the problem set and read it again, and then translate my notes into comments in my code.
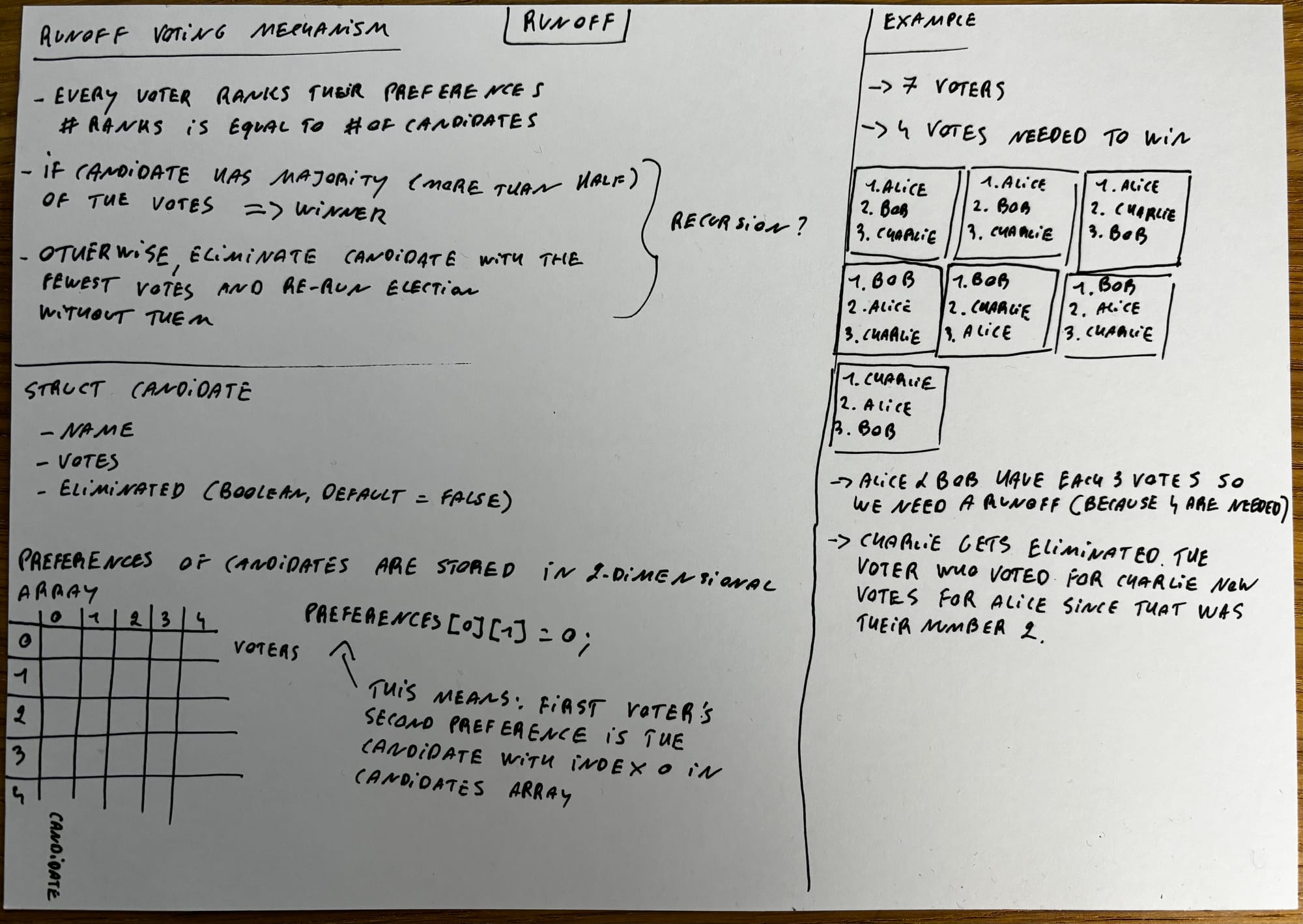
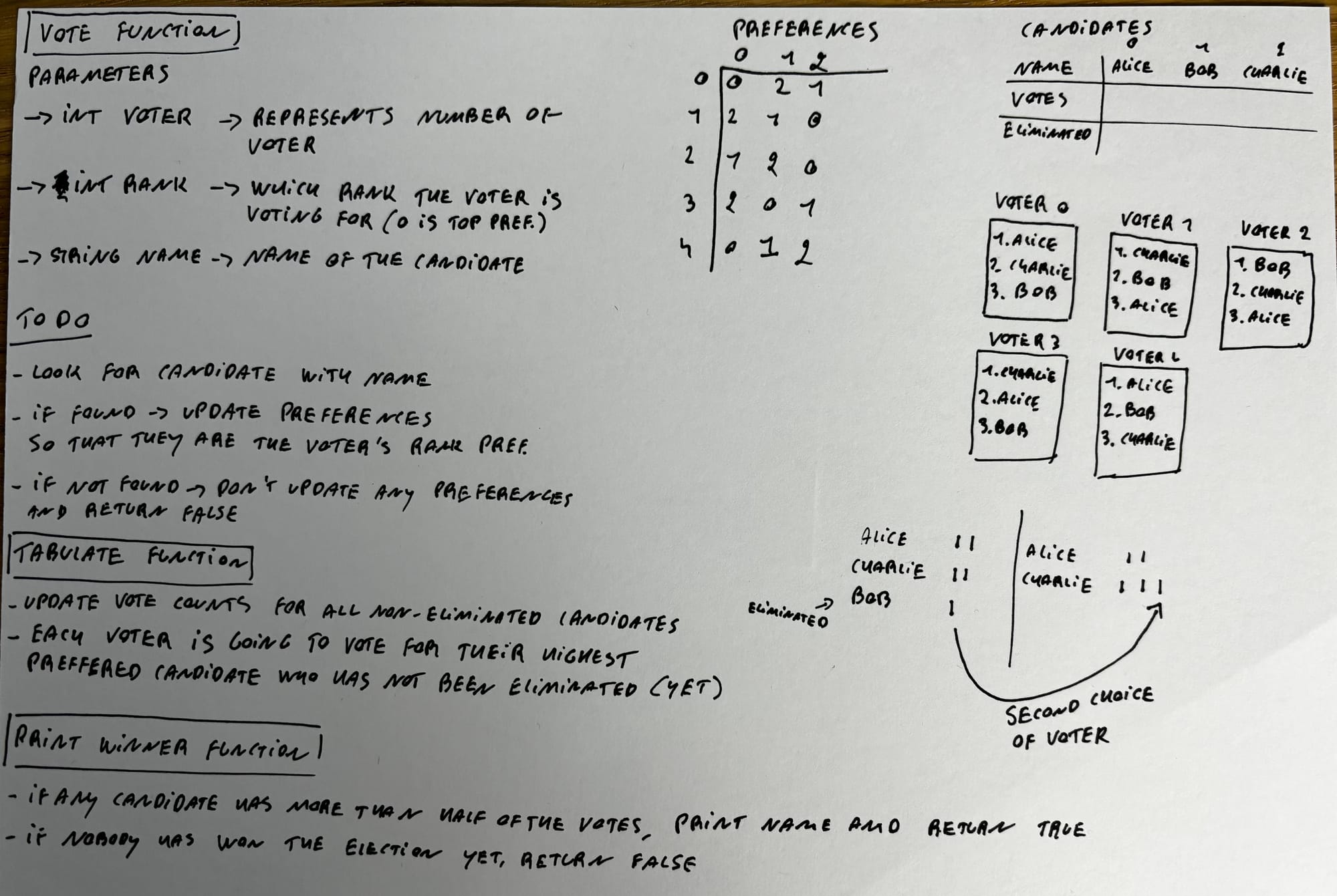

After that, the coding only took about 30 minutes, because it's very straightforward when you know what to do. But if you just rush into the pset and open the IDE without having thoroughly read the problem set, you're probably going to have a bad time.
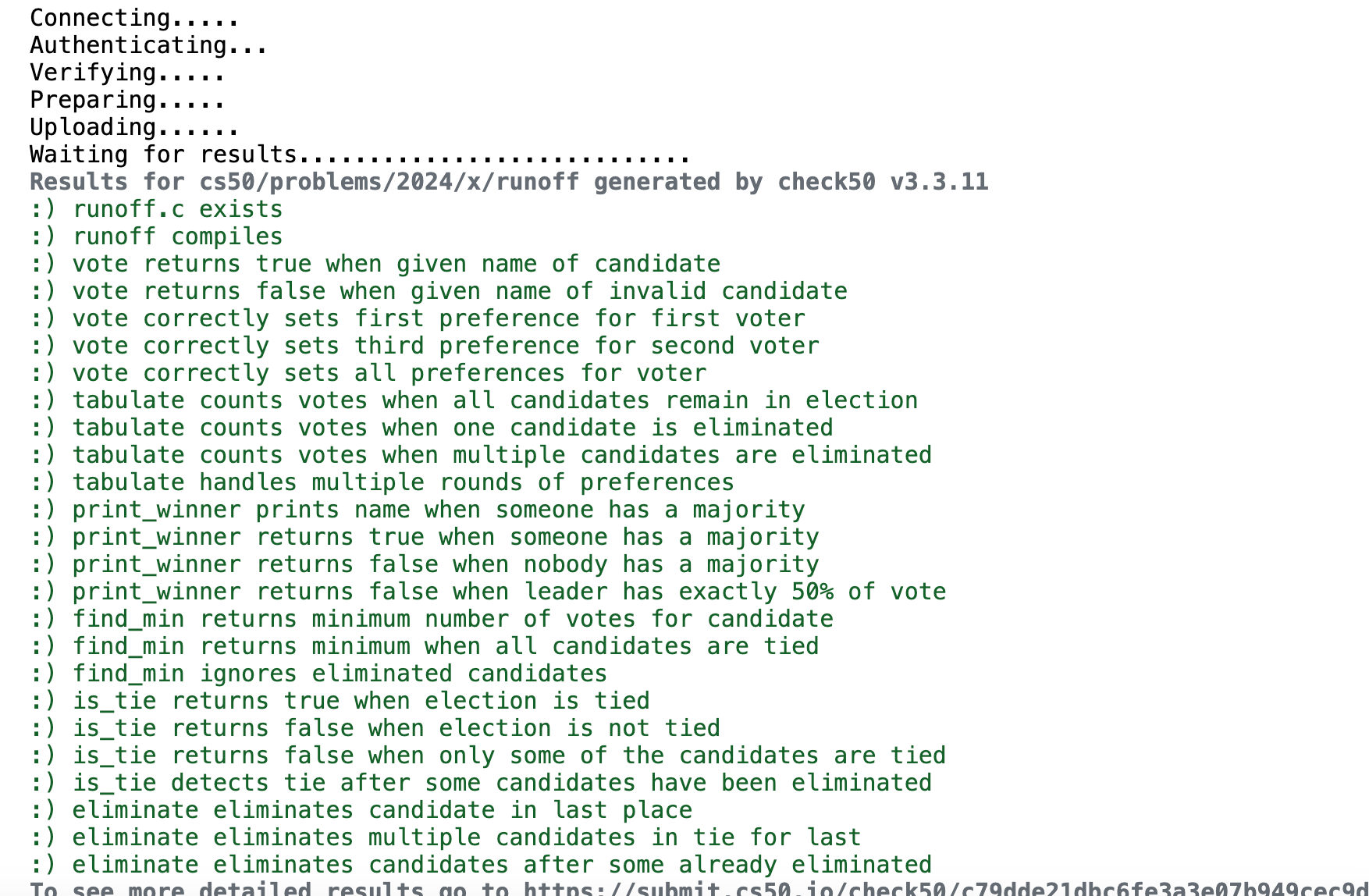
After writing the code, I compiled and immediately ran the check. Green smileys! Except for the two errors with the print_error function. After a long hour (!) I found out that I just had to add "\n" in my printf...
However, it's hard to stay mad with such a satisfying view:
Oh also some other advice, because I can imagine that a lot of people read the comments on the CS50 problem set videos. The comments are filled with people who say it's impossible and that it took them a week to solve, but don't be intimidated by those people. Those may very well be the people that don't take time to read the problem description and just stop and think for a while.
On the other hand, I've also had problem sets where I was having a hard time, and people in the comments said how it was the easiest thing they've ever done. Don't let that take away from your accomplishment. So I guess what I'm trying to say: don't let others intimidate you, and don't compare yourself with others. Just take it at your own tempo.
Check my code here:
thibaultseynaeveTideman
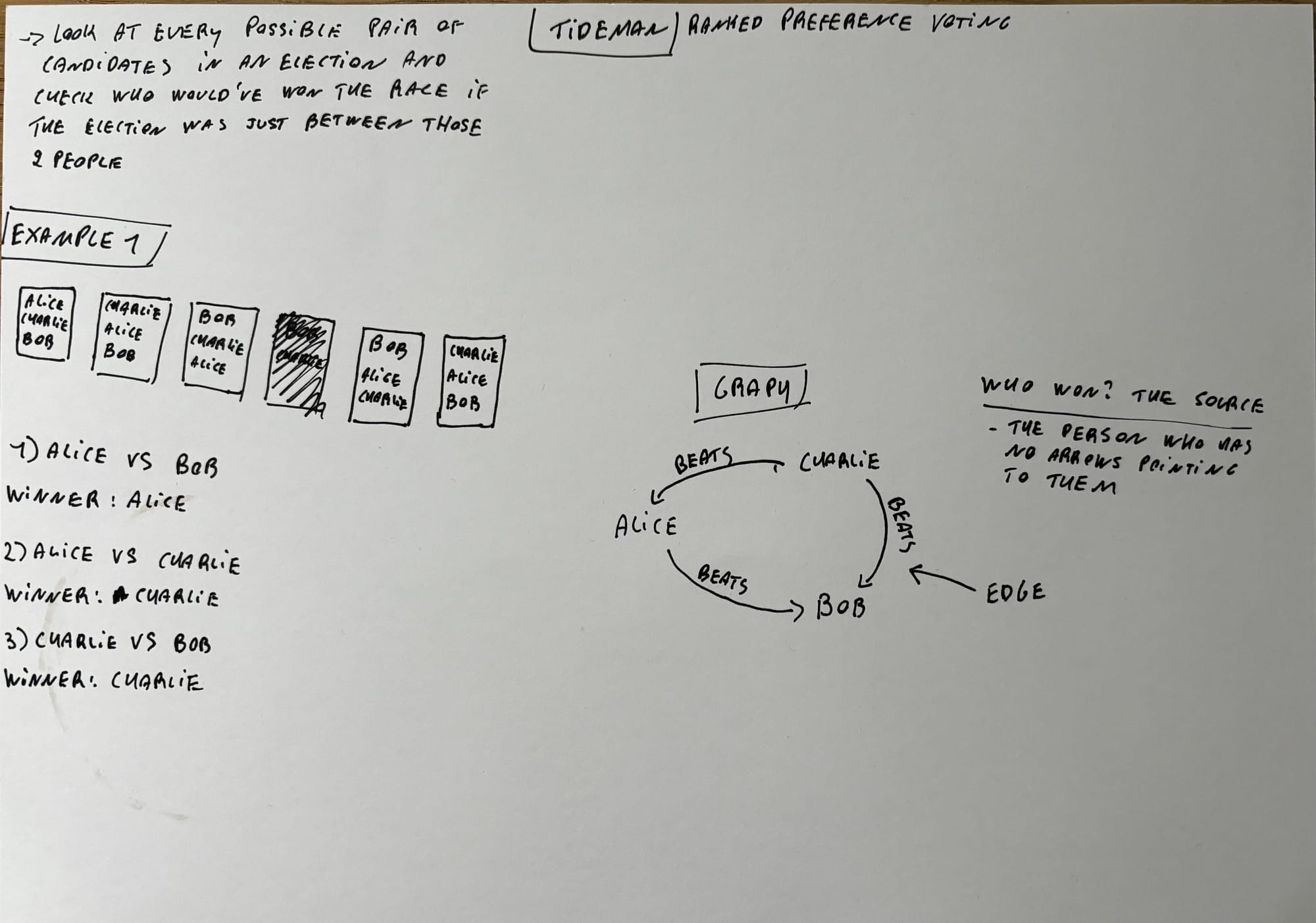
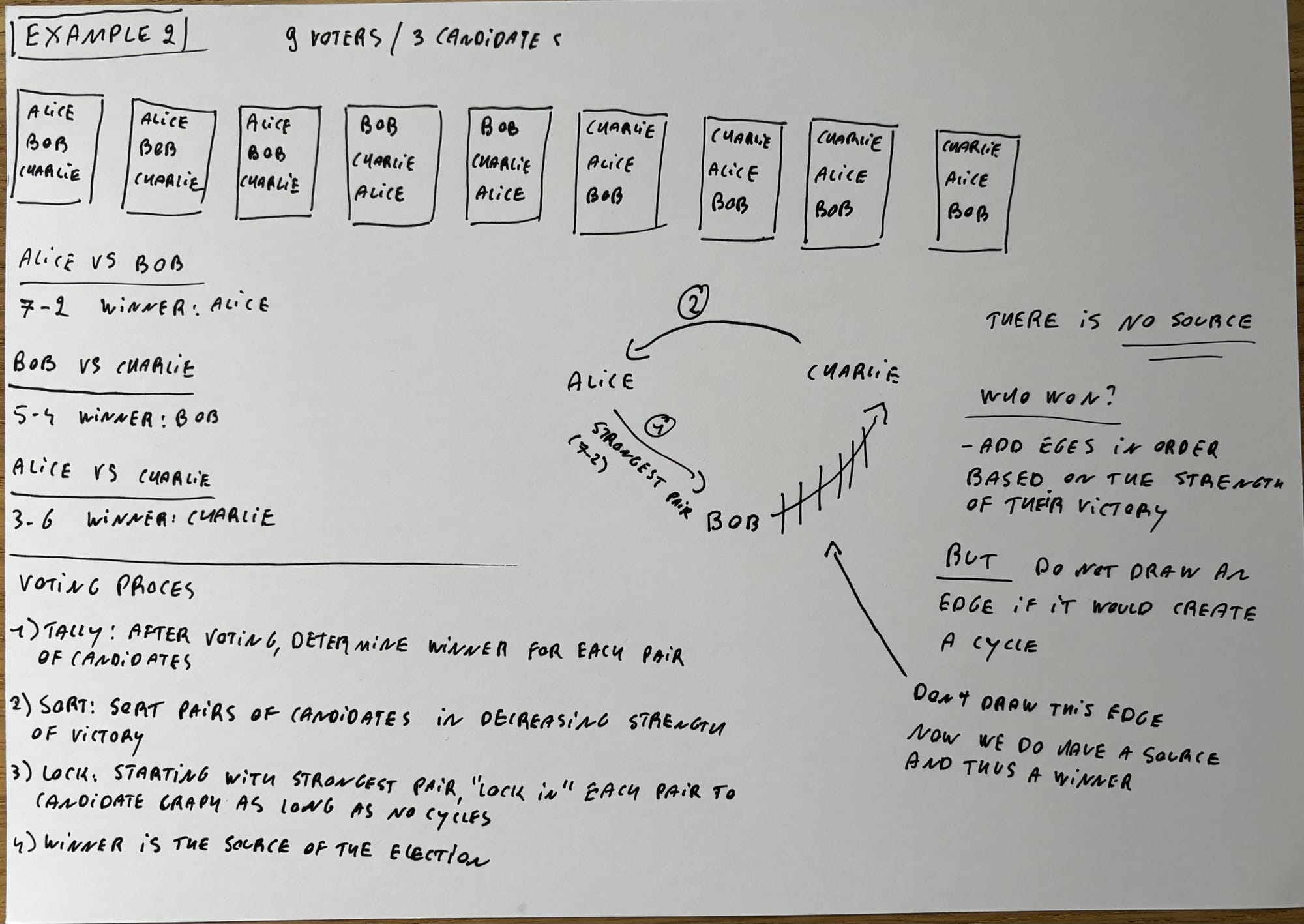
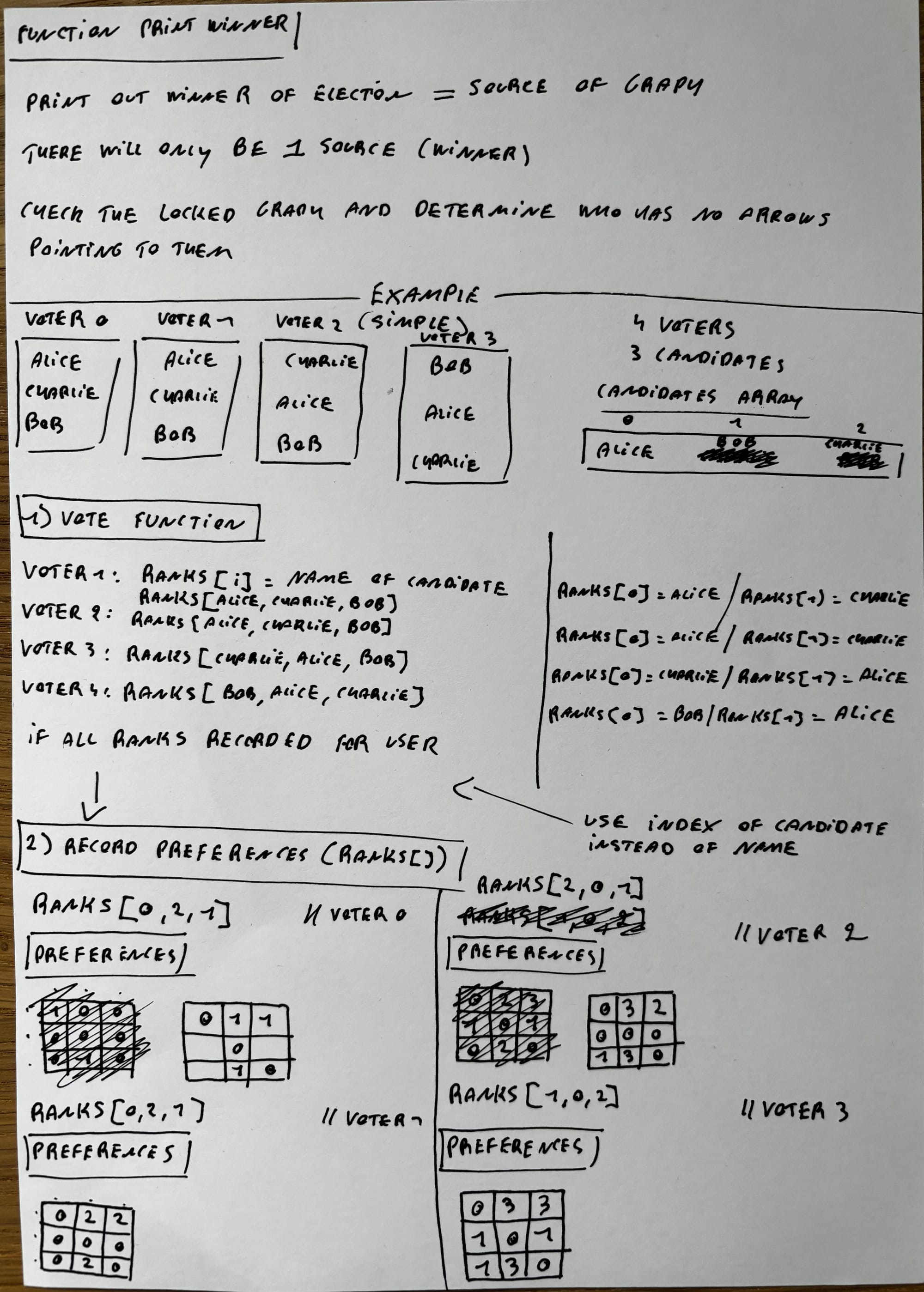
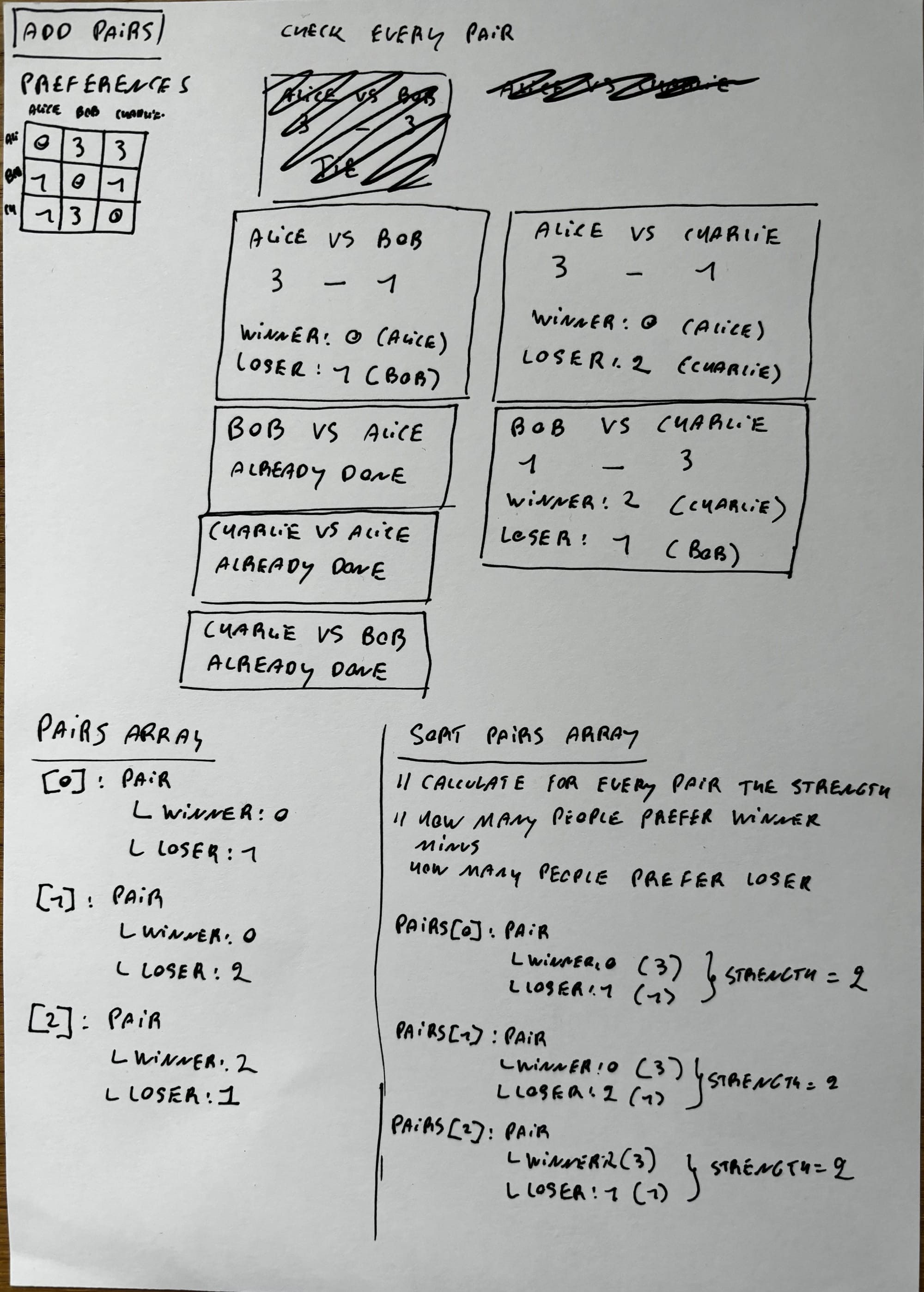
Oh boy. This pset is notoriously challenging and is known as the most difficult problem set in CS50. It's not required to finish the course, but I thought that it would be a good challenge to test how much I've grown as a programmer.
I needed a whole Saturday to finish Tideman. Is it as hard as they claim? I'm afraid I'll have to say yes. It's definitely not impossible, but to get a grasp on the concept of Tideman I had to fill the floor with notes.
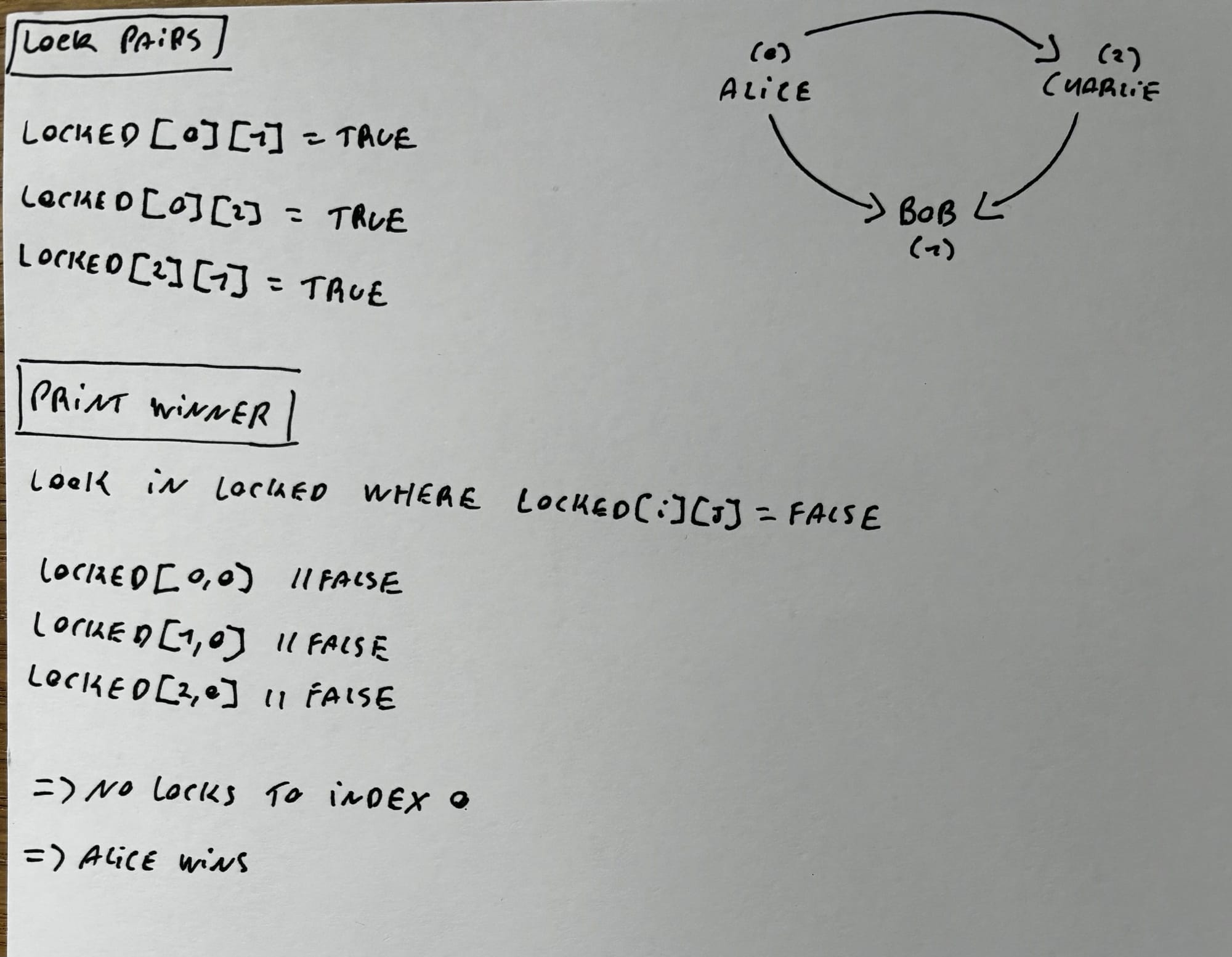
After that, it's a matter of coding everything, but you can feel your brain melt by having to deal with a lot of 2-dimensional arrays en nested for loops. Even when you're going strong, there comes a moment where your brain just can't process all the [i][j]'s anymore and you need to take a break and come back later.
There is also 1 part where you have to use recursion, so if you don't understand that concept it'll be hard to implement it on yourself.
It's also just a very long problem set. It feels like there's always "one more thing" after you have a breakthrough and finish a part of the problem.
But don't let me bring you down! If you're going to do it (it's not obligated to finish CS50), really take your time to understand the problem. I went through the video and wrote everything down. After that, I went through an example of my own and asked myself at every step "what value do I expect the variables to have here".
One important note if you're going to take on Tideman. In the walkthrough video, it's said that there will only be 1 winner and that you don't have to think about a scenario where multiple candidates will win the election. HOWEVER, the written problem set mentions that there WILL be a scenario where the program must print out multiple names (one for each winner in a tied election).
Maybe my notes can be helpful to you:



 thibaultseynaeve
thibaultseynaeve